

Golang panic and recover
Golang panic recoverRecover主要用于捕获异常 让程序回到正常状态 而且必须要在defer func()函数中间使用才可以 否则无法阻止panic调用panic之后会立刻停止执行当前函数的剩余代码 并在当前goroutine中递归执行调用方的defer
调用runtime.deferprocStack创建defer对象 总共有三种模式:
第一种,堆上分配(deferproc),基本是依赖运行时来分配”_defer”对象并加入延迟参数。在函数的尾部插入deferreturn方法来消费deferlink第二种,栈上分配(deferprocStack),基本上跟堆差不多,只是分配方式改为在栈上分配,压入的函数调用栈存有_defer记录,编译器在ssa过程中会预留defer空间第三种,开放编码模式(open coded),不过是有条件的,默认open-coded最多支持8个defer,超过则取消。在构建ssa时如发现gcflags有N禁止优化的参数 或者 return数量 * defer数量超过了 15不适用open-coded模式。并不能处于循环中

Ar ...
Golang Map问题
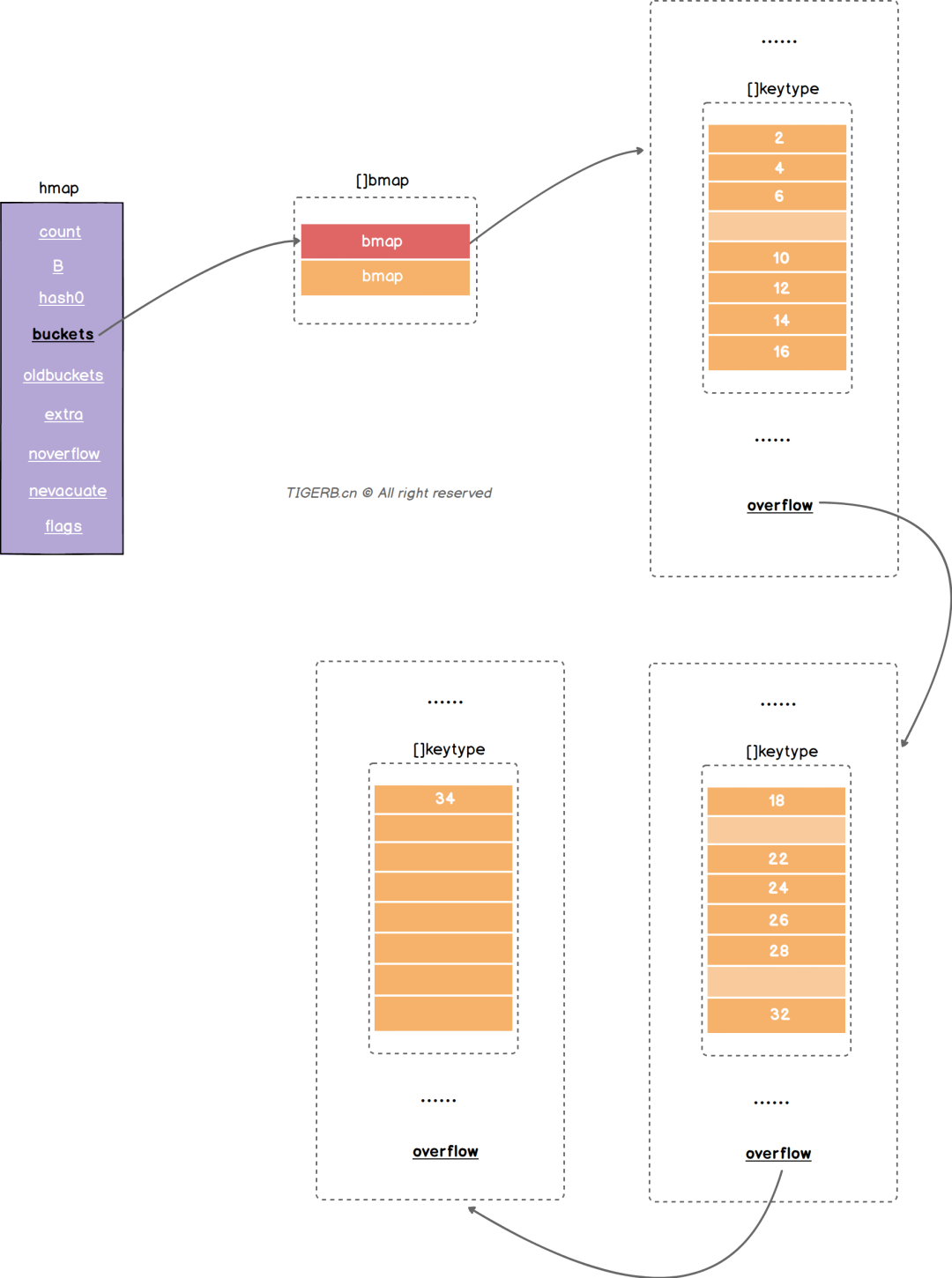
Map问题Map无序问题
正常写入(非哈希冲突写入) 是hash到某一个bucket上面 而不是按照buckets顺序写入 虽然buckets是一块连续的内存 但是新写入的键值可能写到这个bucket 也可能写到其他的bucket上面
哈希冲突写入 如果存在哈希冲突 就会写到同一个bucket上面 可能是一个bmap的elems任何位置 甚至可能是溢出桶里面
Map扩容问题Go的Map扩容有两种: 1. 成倍扩容 2. 等量扩容
当map写操作的时候 会触发成倍扩容当元素数量或者bucket数量大于6.5的时候 也会触发成倍扩容
成倍扩容的过程:
原始的buckets被指向oldbuckets
重新初始化成倍的新的buckets指向buckets
写操作触发扩容
每次仅仅扩容当前的键对应的bucket(bmap)
原先的bmap被分流到两个新的bucket(bmap)中间
当bmap的溢出桶数量 大于等于2*B的时候 触发等量扩容 是为了整理溢出的桶 回收冗余的溢出桶
等量扩容不会修改元素的顺序
123456789// 等量扩容判断func tooManyOverflow ...
Golang内存对齐
阅读博客 https://segmentfault.com/a/1190000040528007 记录
虚拟内存就是在程序和物理内存之间引入一个中间层 这个中间层就是虚拟内存 就实现了对进程地址和物理地址的隔离
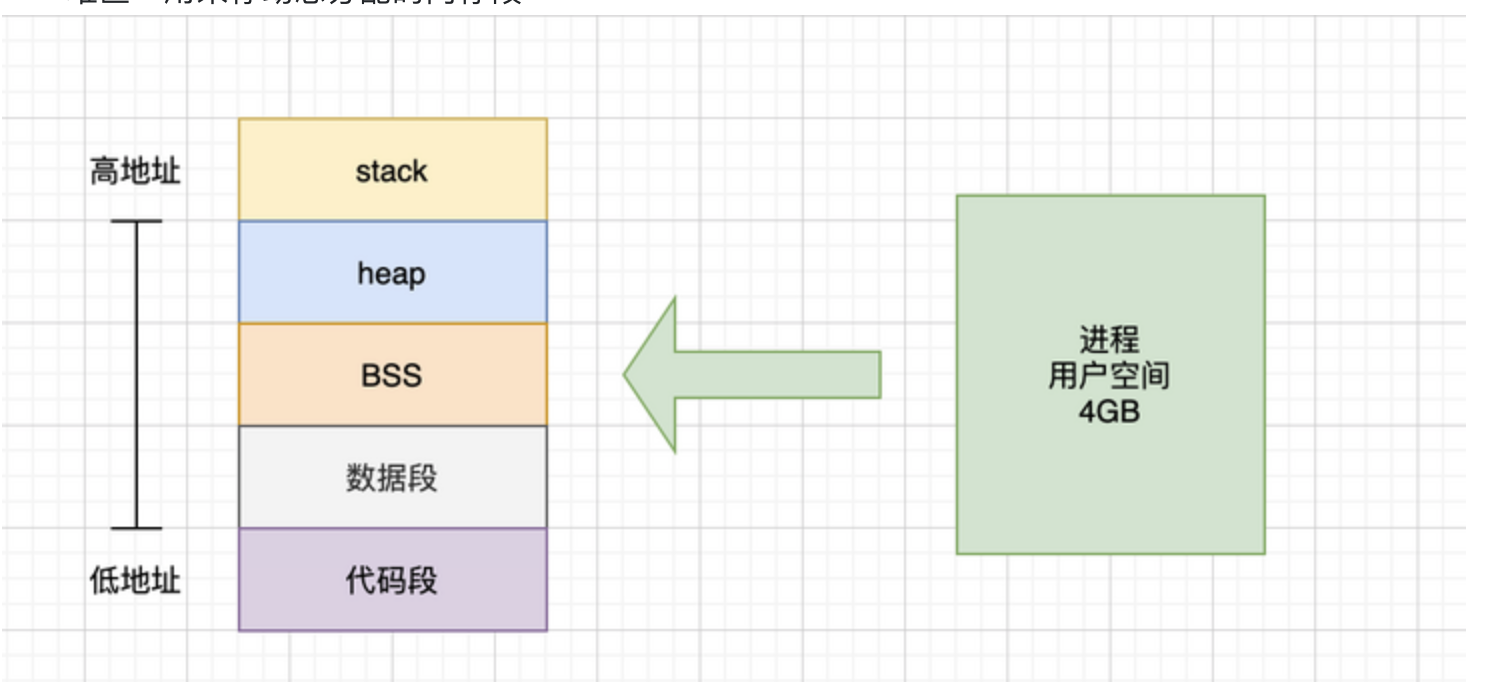
内存中间是划分为用户空间和内核空间的
用户空间分成了5个不同的内存区域
代码段 存放可执行文件的操作指令 只读
数据段 用来存放可执行文件中间已经初始化的全局变量 存放静态变量和全局变量
BSS段 用来存放没有初始化的全局变量
堆区 存放动态分配的内存段
栈区 用来存放临时创建的局部变量

编译器:编译器就是将“一种语言(通常为高级语言)”翻译为“另一种语言(通常为低级语言)”的程序。一个现代编译器的主要工作流程:源代码 (source code) → 预处理器(preprocessor) → 编译器 (compiler) → 目标代码 (object code) → 链接器 (Linker) → 可执行程序(executables)。
内存对齐是指首地址对齐 而不是说每个变量大小对齐 需要内存对齐的原因:
有些CPU可以访问任意位置数据 但是有些只 ...
IO模型
同步IO 异步IO 阻塞IO 非阻塞IO
阻塞和非阻塞的区别: 线程是否挂起异步和同步的区别: 主动和被动的通知方式
周转时间: 任务到达到任务完成之间的时间响应时间: 任务到达到任务首次被调度的时间
要求高的平均周转时间,必然降低平均响应时间
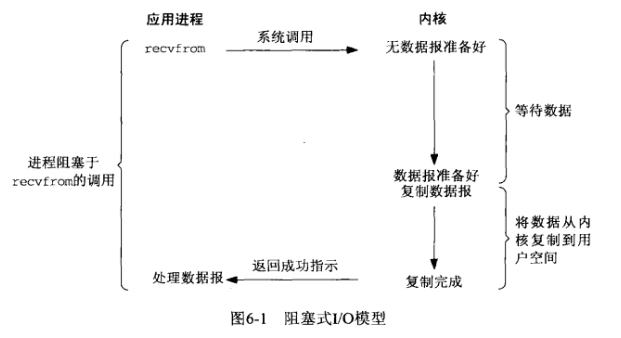
同步IO:阻塞IO: 就是某一个请求 请求过去之后 被请求的没有准备好 请求方要一直等着对方准备好 然后将数据给出来之后才能去做其他事情非阻塞IO: 就是请求过去 对方告诉我我还没准备好 我就走开做其他的 等一下再来请求 如果还是没有就又离开做其他的 当哪次请求有了的时候就要一直等到拿到所需要的东西了 才能走开 这个拿数据的过程是不能走开的 其实 应该还是个同步IO信号驱动IO模型: 注册一个信号函数 当我需要的东西准备好了 再通知我去获取 但是获取的这个过程中间 我还是不能做其他的 觉得应该还是同步IO异步IO模型: 一个调用过去 我可以不关心数据是不是没准备好 被调用房将数据准备好了 放到指定位置了 通知我 已经好了 这个期间我可以做其他的的事情 也不用等着接收数据
POSIX同步IO、异步IO、阻塞IO、非阻塞IO,这几个词常见于各种 ...
Golang内存管理-垃圾回收
Golang 内存管理(三) 垃圾回收Golang gc发展进程
1.1 版本: 标记+清除方式,整个过程需要 STW(stop the world,挂起所有用户 goroutine)1.3 版本: 标记过程 STW,清除过程并行1.5 版本: 标记过程使用三色标记法1.8 版本: Hibrid Write Barrier
标记清除
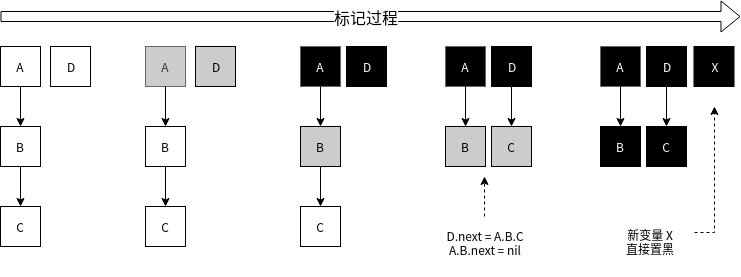
垃圾回收的算法很多,比如最常见的引用计数,节点复制等等。Go 采用的是标记清除方式。当 GC 开始时,从 root 开始一层层扫描,这里的 root 区值当前所有 goroutine 的栈和全局数据区的变量(主要是这 2 个地方)。扫描过程中把能被触达的 object 标记出来,那么堆空间未被标记的 object 就是垃圾了;最后遍历堆空间所有 object 对垃圾(未标记)的 object 进行清除,清除完成则表示 GC 完成。清除的 object 会被放回到 mcache 中以备后续分配使用
Go 的内存mheap区域中有一个 bitmap 区域,就是用来存储 object 标记的
最开始 Go 的整个 GC 过程需要 STW,因为用户进程如果在 G ...
Golang内存管理(二)
Golang内存管理Go 的内存管理基本上参考 tcmalloc 来实现的, Go 的内存是自动管理的,我们可以随意定义变量直接使用,不需要考虑变量背后的内存申请和释放的问题
TCMalloc:GO:
mheap里保存了两棵二叉排序树,按span的page数量进行排序:free:free中保存的span是空闲并且非垃圾回收的span。scav:scav中保存的是空闲并且已经垃圾回收的span。如果是垃圾回收导致的span释放,span会被加入到scav,否则加入到free,比如刚从OS申请的的内存也组成的Span。
mheap与PageHeap也有不同点:mheap把Span组织成了树结构,而不是链表,并且还是2棵树,然后把Span分配到heapArena进行管理,它包含地址映射和span是否包含指针等位图,这样做的主要原因是为了更高效的利用内存:分配、回收和再利用

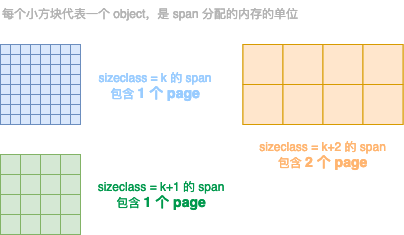
object size:代码里简称size,指申请内存的对象大小。size class:代码里简称class,它是size的级别,相当于把size归类到一定大小的区间段,比如size[1,8]属于 ...
Golang内存管理(一)
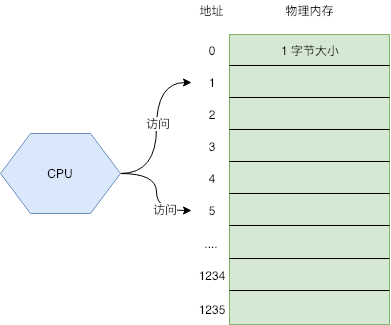
可以把内存看成一个数组,每个数组元素的大小是 1B,也就是 8 位(bit)。CPU 通过内存地址来获取内存中的数据,内存地址可以看做成数组的游标(index)
CPU 在执行指令的时候,就是通过内存地址,将物理内存上的数据载入到寄存器,然后执行机器指令,但随着发展,出现了多任务的需求,也就是希望多个任务能同时在系统上运行。这就出现了一些问题:内存访问冲突:程序很容易出现 bug,就是 2 或更多的程序使用了同一块内存空间,导致数据读写错乱,程序崩溃。更有一些黑客利用这个缺陷来制作病毒。内存不够用:因为每个程序都需要自己单独使用的一块内存,内存的大小就成了任务数量的瓶颈。程序开发成本高:你的程序要使用多少内存,内存地址是多少,这些都不能搞错,对于人来说,开发正确的程序很费脑子。
虚拟内存虚拟内存的出现,很好的为了解决上述的一些列问题。用户程序只能使用虚拟的内存地址来获取数据,系统会将这个虚拟地址翻译成实际的物理地址对于内存不够用的问题,虚拟内存本质上是将磁盘当成最终存储,而主存作为了一个 cache。程序可以从虚拟内存上申请很大的空间使用,比如 1G;但操作系统不会真的在物理内存上 ...
常见并发模型
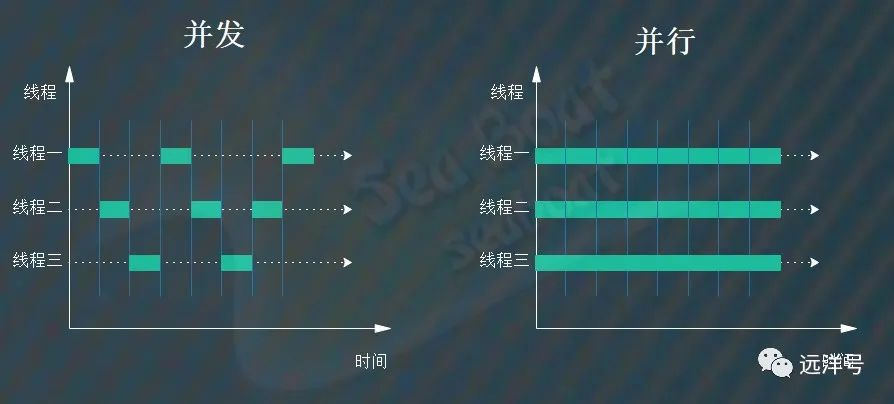
常见的并发模型[Fork/Join Reactor Proactor Actor CSP]并发和并行都是相对于进程和线程来说的,并发是指一个或者若干个CPU对多个进程或者线程之间进行多路复用 就是cpu轮着执行多个任务 每个任务执行一段时间 并行则是指多个进程或者线程同一时刻被执行 是真正意义的同时执行 必须多个cpu的支持
如果 对于并发来说 是线程一执行一段时间 二执行一段时间 三再执行一段时间 没个线程轮流的到cpu的执行时间 这种情况只需要一个cpu就可以实现 对于并行来说 线程一二三是同时执行 需要三个cpu ,当然 并发和并行都提升了cpu的资源利用效率
关于并发模型拥有多个cpu的现代计算机 依靠并发并行机制能更快的执行任务 但是如何通过并发并行来执行一个任务也有多种不同的方式 就是不同的并发模型, 不同的并发模型对任务的拆分也是不同的 线程之间的通信方式也是不同的, 由于并发模型规定了任务描述 执行方式和线程协作等的总体框架 所以并发模型设计 需要考虑 如简化对任务的描述 让并发高效 让开发人员更加方便实现并发
任务模型:
从进程与线程角度 ...
关系型数据库的瓶颈和优化
数据库分类数据库大致可以分为传统的关系型数据库 mysql oracle sqlserver postgresql等
非关系型数据库 hbase(列式数据库) mongodb 文档型数据库 redis 高性能kv存储 lucene 搜索引擎等
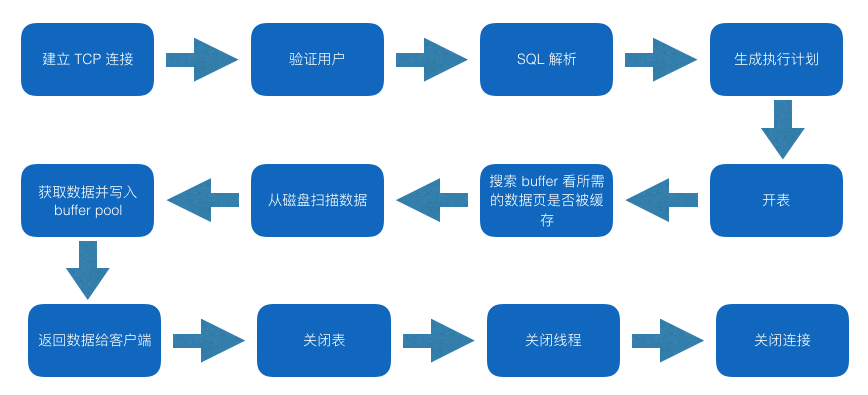
数据库查询开销

这个中间耗时操作有 建立TCP链接 生成执行计划 开表 从磁盘扫描数据 关闭链接
在mysql中间 主键查询是最为高效的一类查询
索引字段如果太长 会导致order by无法在内存中见完成排序 使用mysql磁盘排序 并没有使用索引的排序
在mysql中间 数据按照页的方式来组织 默认大小16KB 包括页头 页尾 中间是记录如果表中间存在大字段 达到了甚至超过了单页的大小 这个时候db就会新开一个数据页 当前页通过指针指向该页 一页不够 就会不断增加数据页直到可以存下为止 那么这个时候查询开销是很大的 严重的时候导致热页换出 引起系统抖动 ,
用了缓存 可能会有 缓存命中 缓存穿透 缓存失效 缓存一致性问题
读写分离的原理就是将数据库读写操作分散到不同的节点上

数据库服务器搭建主从集群 主负责写操作 从负责读 ...

Hello World
生成新的文章1$ hexo new "My New Post"
更多: Writing
运行1$ hexo server
更多: Server
生成1$ hexo generate
更多: Generating
部署1$ hexo deploy
更多: Deployment
常用命令[注意以下命令需要切换到blog文件夹(cd blog)执行]1234567891011hexo n "文章名称" => hexo new "文章名称" #这两个都是创建新文章,前者是简写模式,下同,new后面加一个draft可以生成草稿hexo p => hexo publish # 发布草稿hexo g => hexo generate # 生成hexo s => hexo server # 启动服务预览hexo d => hexo deploy # 部署 hexo server # Hexo 会监视文件变动并自动更新,无须重启服务器。hexo server -s # 静态模式h ...