Golang Map问题
Map问题
Map无序问题
- 正常写入(非哈希冲突写入) 是hash到某一个bucket上面 而不是按照buckets顺序写入 虽然buckets是一块连续的内存 但是新写入的键值可能写到这个bucket 也可能写到其他的bucket上面
- 哈希冲突写入 如果存在哈希冲突 就会写到同一个bucket上面 可能是一个bmap的elems任何位置 甚至可能是溢出桶里面
Map扩容问题
Go的Map扩容有两种: 1. 成倍扩容 2. 等量扩容
当map写操作的时候 会触发成倍扩容
当元素数量或者bucket数量大于6.5的时候 也会触发成倍扩容
成倍扩容的过程:
- 原始的buckets被指向oldbuckets
- 重新初始化成倍的新的buckets指向buckets
- 写操作触发扩容
- 每次仅仅扩容当前的键对应的bucket(bmap)
- 原先的bmap被分流到两个新的bucket(bmap)中间
当bmap的溢出桶数量 大于等于2*B的时候 触发等量扩容 是为了整理溢出的桶 回收冗余的溢出桶
等量扩容不会修改元素的顺序
1 | // 等量扩容判断 |
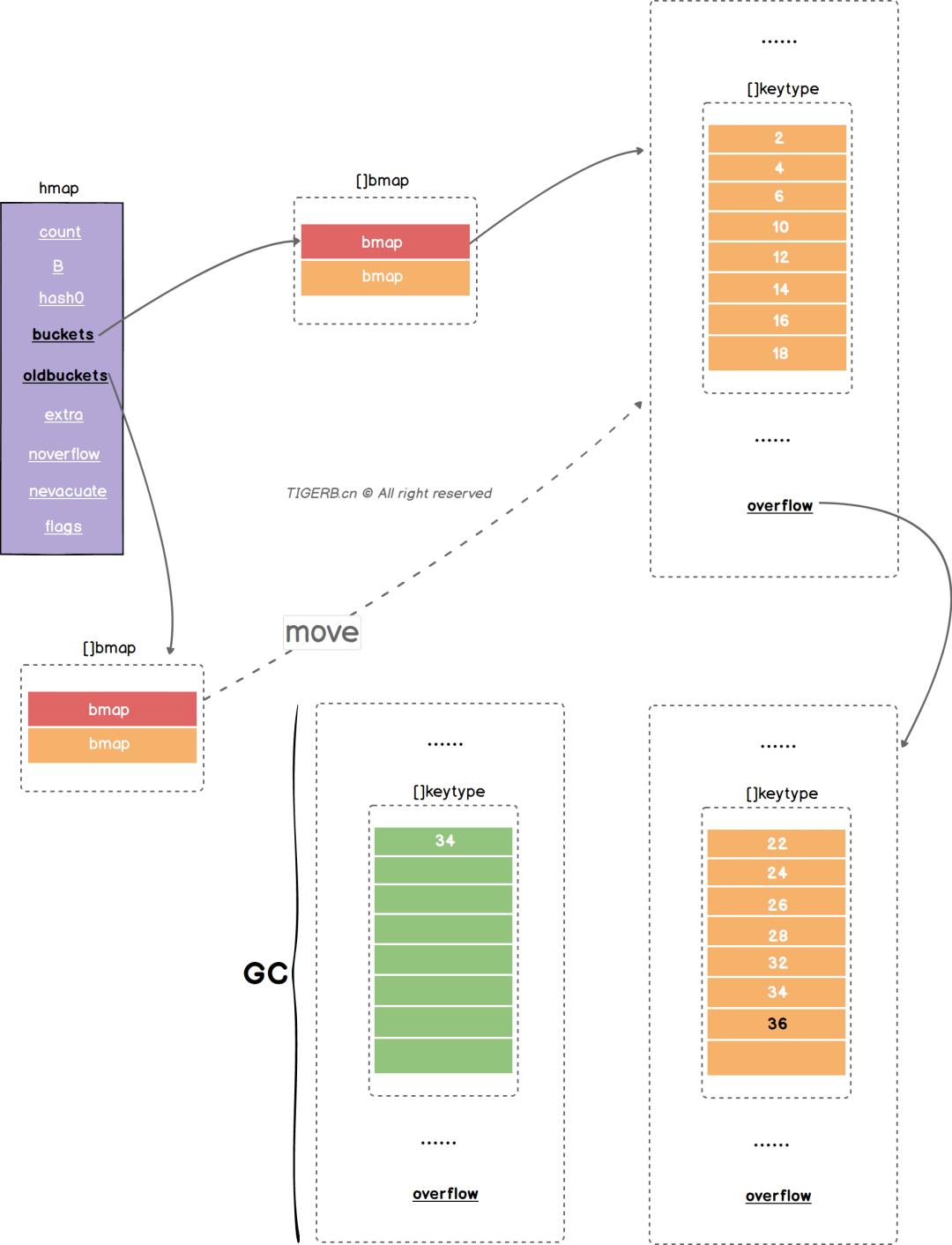
条件1. 否会触发「等量扩容」的公式:noverflow >= uint16(1)<<(B&15)
条件2. 上文我们已经假设:忽略索引为1的的bucket(也就是buckets的第2个bmap),仅以索引为0的bucket(也就是buckets的第1个bmap)里的键值为例
可得:noverflow = 2
B = 1
我们套入这个公式:2 >= 1 << (0001 & 1111)
2 >= 1 << 0001
2 >= 0010
2 >= 2
得到结果:true
Map读写问题
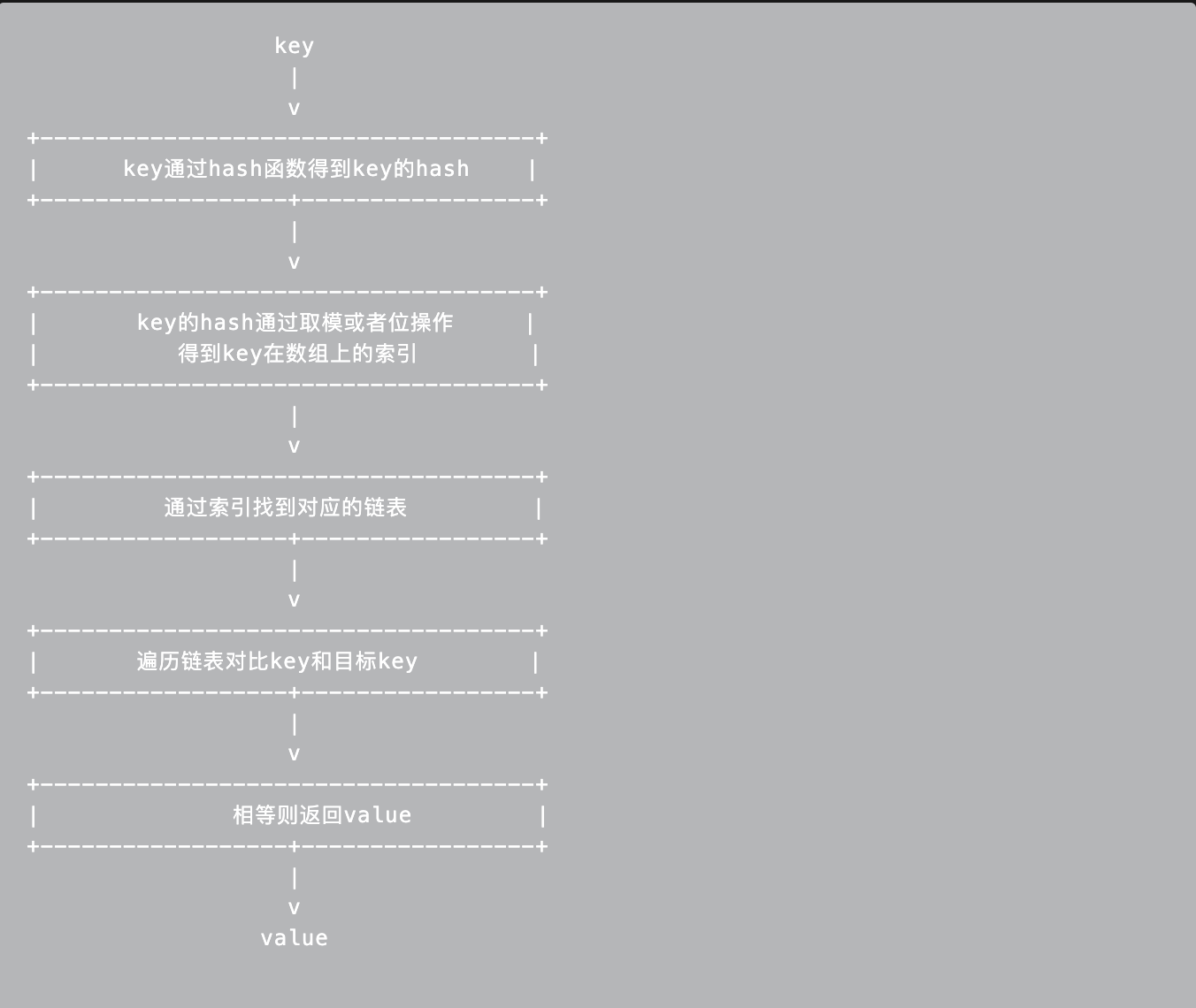
读取一个key的过程大致如下:
- key通过hash函数得到key的hash
- Key的hash通过取模或者位操作得到key在数组上的索引【golang: 哈希和数组的长度通过位操作获取数组位置的索引】
- 通过索引找到对应的链表
- 遍历链表对比key和目标key 相等则返回value
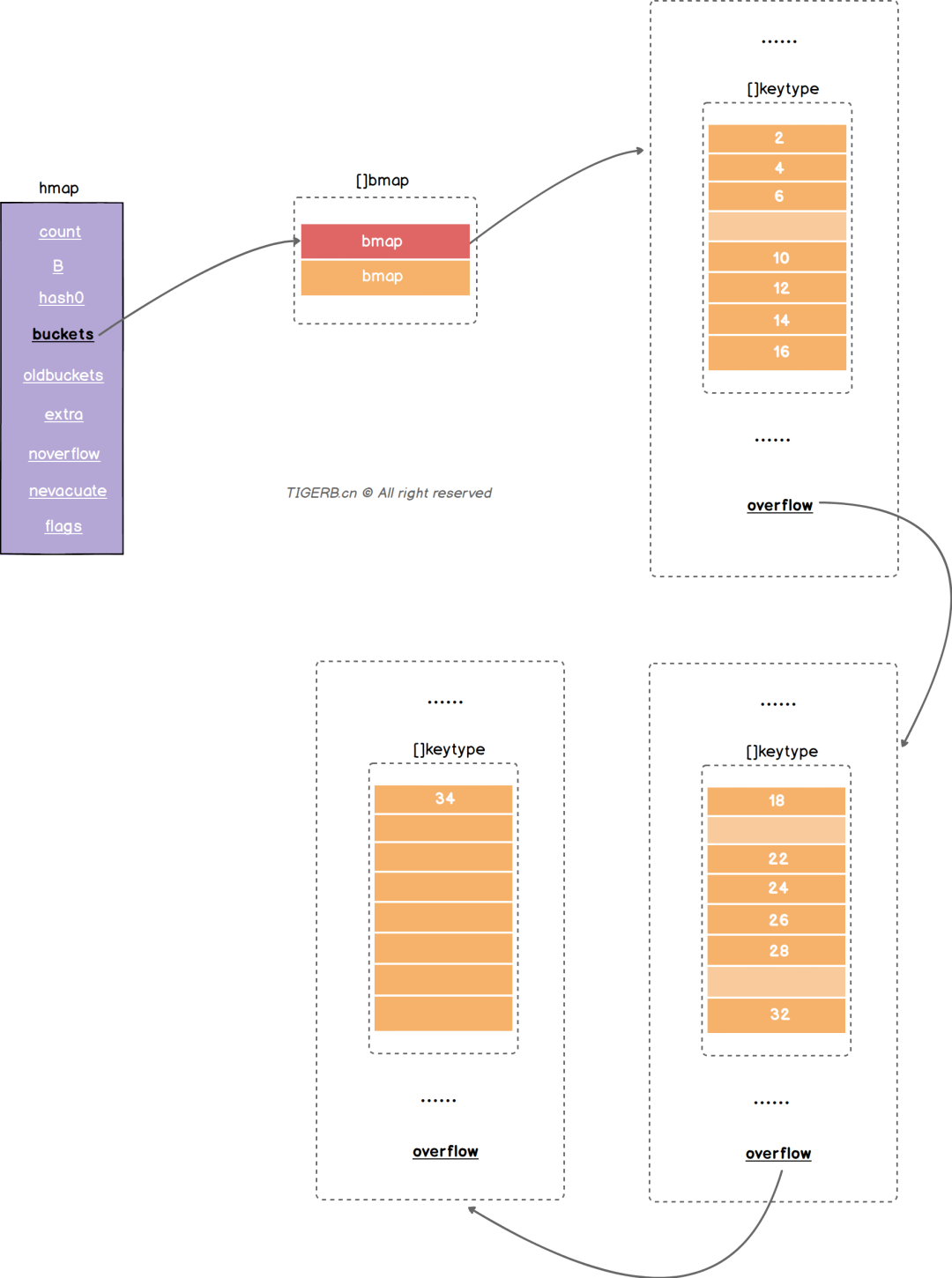
Go语言解决hash冲突不是链表 是记住要用的数组(内存上的连续空间) 并且不是使用一个数组 而是使用两个数组分别存储键和值
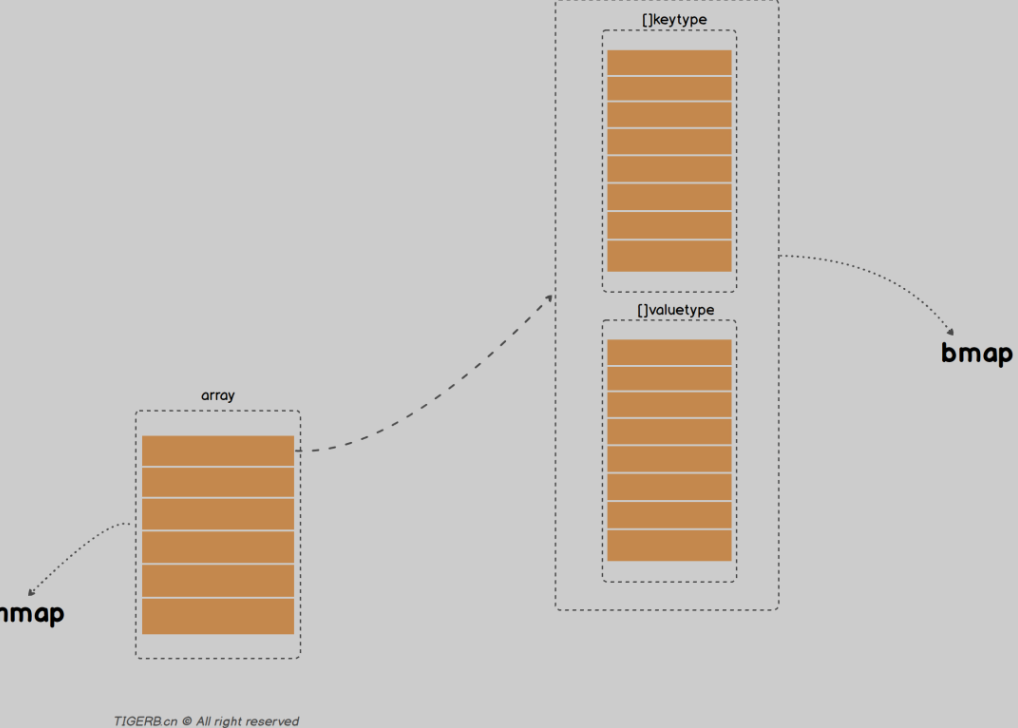
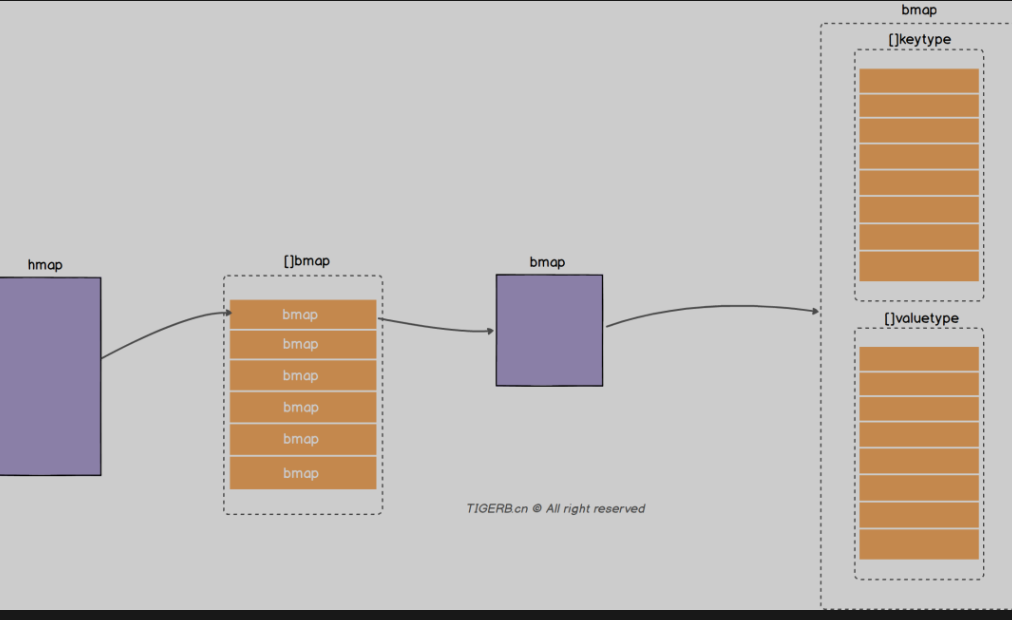
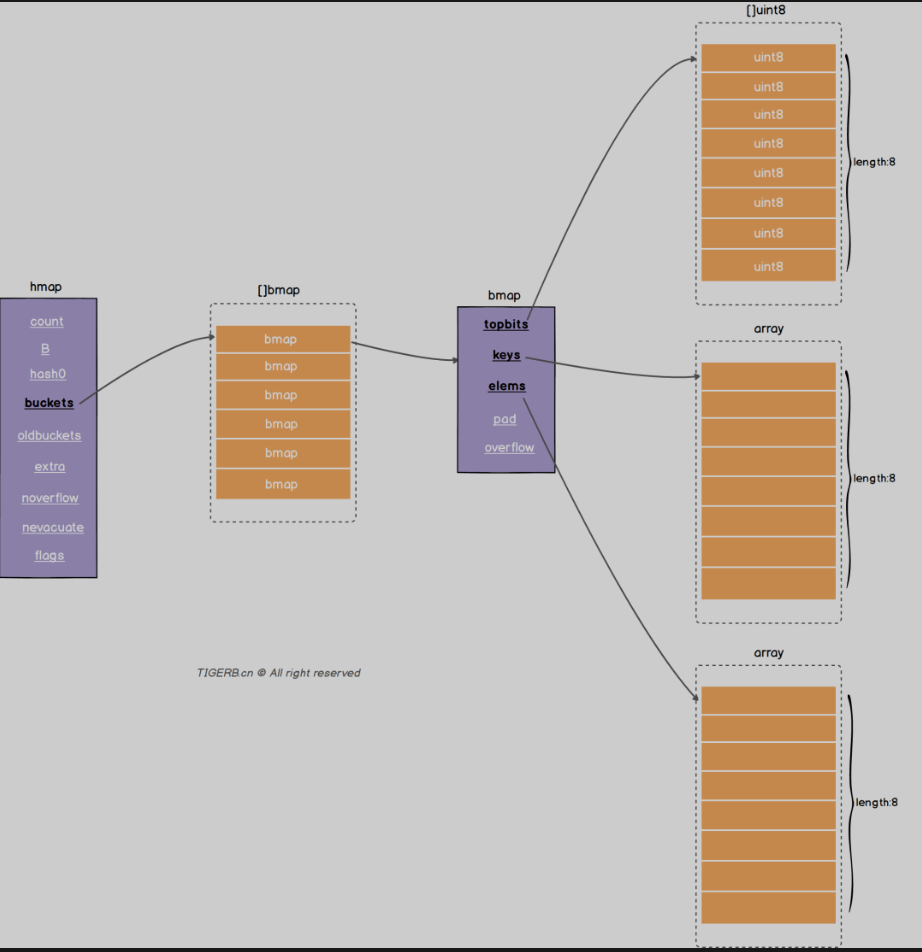
分别对应的是两个核心的结构体 hmap和bmap bmap里面两个数组 分别存放key和value
Hmap的结构 :
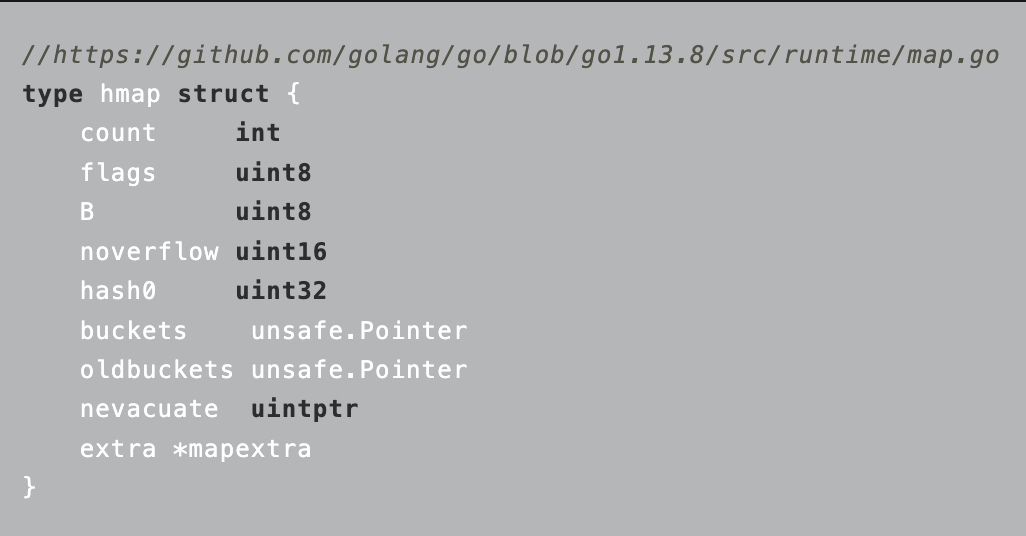
count: 键值对的数量,
B: 2^B=len(busckets)
Hash0: hash因子
Buckets: 指向一个数组(连续内存空间), 数组的类型是[]bmap 就是正常桶
oldbuckets: 扩容的时候存放之前的buckets
Extra:溢出桶结构 正常桶里面bmap存满了 会使用这里的内存空间存储空间存放键值对
noverflow:溢出桶里面的bmap的大致的数量
nevacuate:分流次数 成倍扩容分流操作计数的字段(map扩容相关字段)
Flags: 状态标识 正在被写 正在遍历 等量扩容等
Bmap的结构:
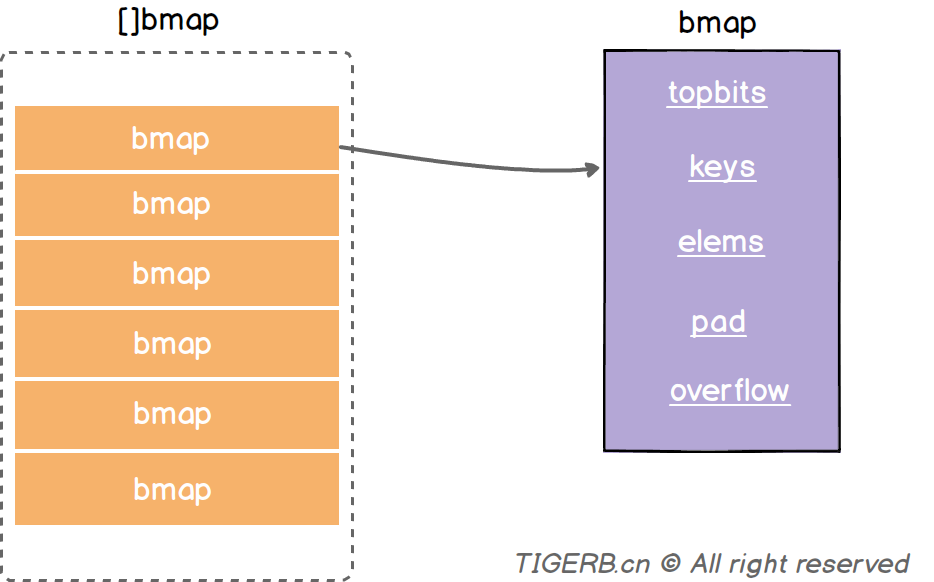

Topbits: 长度为8的数组 []uint8 元素为: key获取的hash的高8位 遍历对比的时候使用
Keys:长度为8的数组 []keybyte 具体的key值
Elems: 长度为8的数组 []elemtype 原属为键值对的key对应的值
overflow: 指向的hmap.extra.overflow 的bmap 上面的最多村8个 满了就指向这个bmap 存放的就是正常桶满了之后关联的溢出桶bmap地址 当map写操作的时候
Pad: 对其内存使用的 不是每个bmap都有 需要满足条件
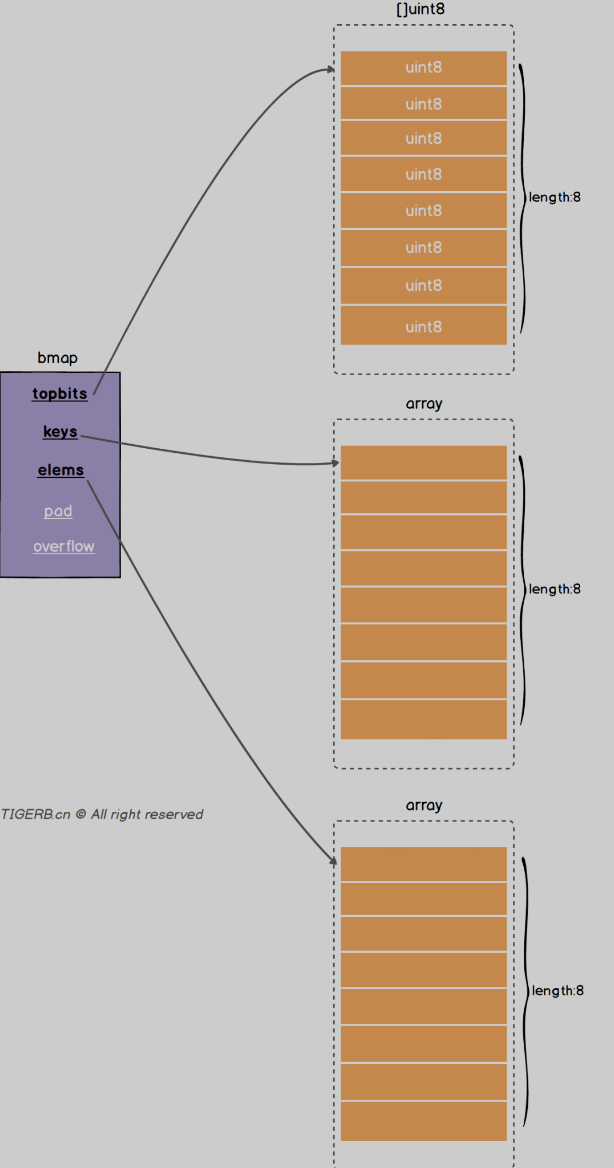
每个bmap最多存放8组键值对
正常桶Bmap满了之后的操作:
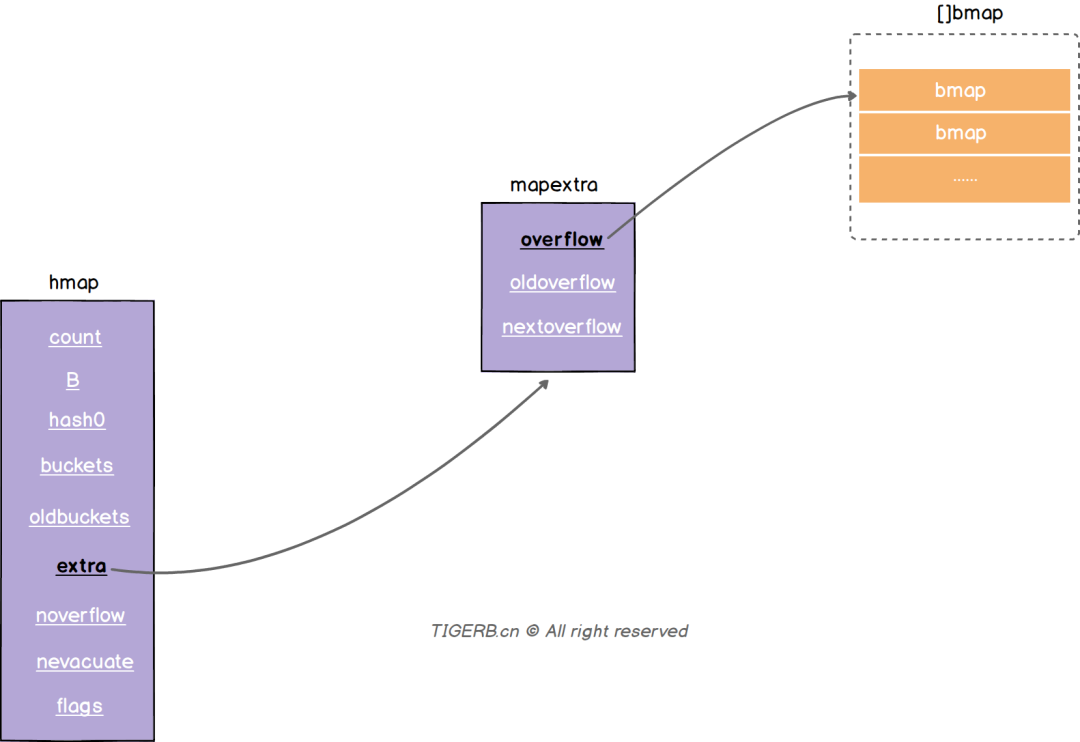
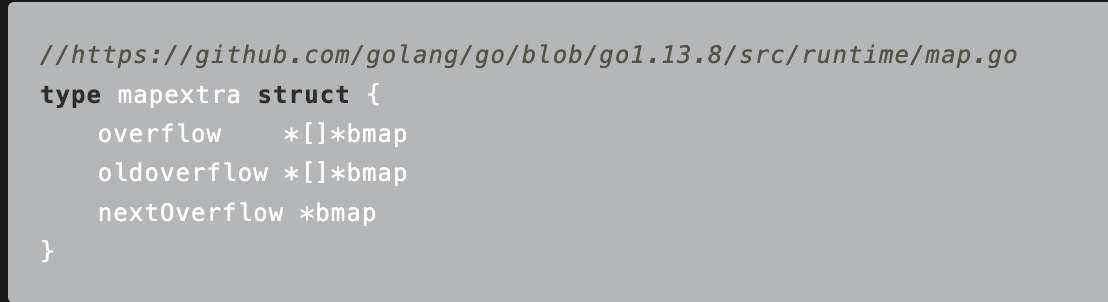
Overflow: 溢出桶 和hmap.buckets一样也是数组 []bmap 当正常桶满了之后就是用map.extra.overflow的bmap
oldoverflow : 扩容时存放之前的overflow
nextoverflow: 指向溢出桶下一个可以使用的bmap
Map写操作关键代码:
1 | // https://github.com/golang/go/blob/go1.13.8/src/runtime/map.go |
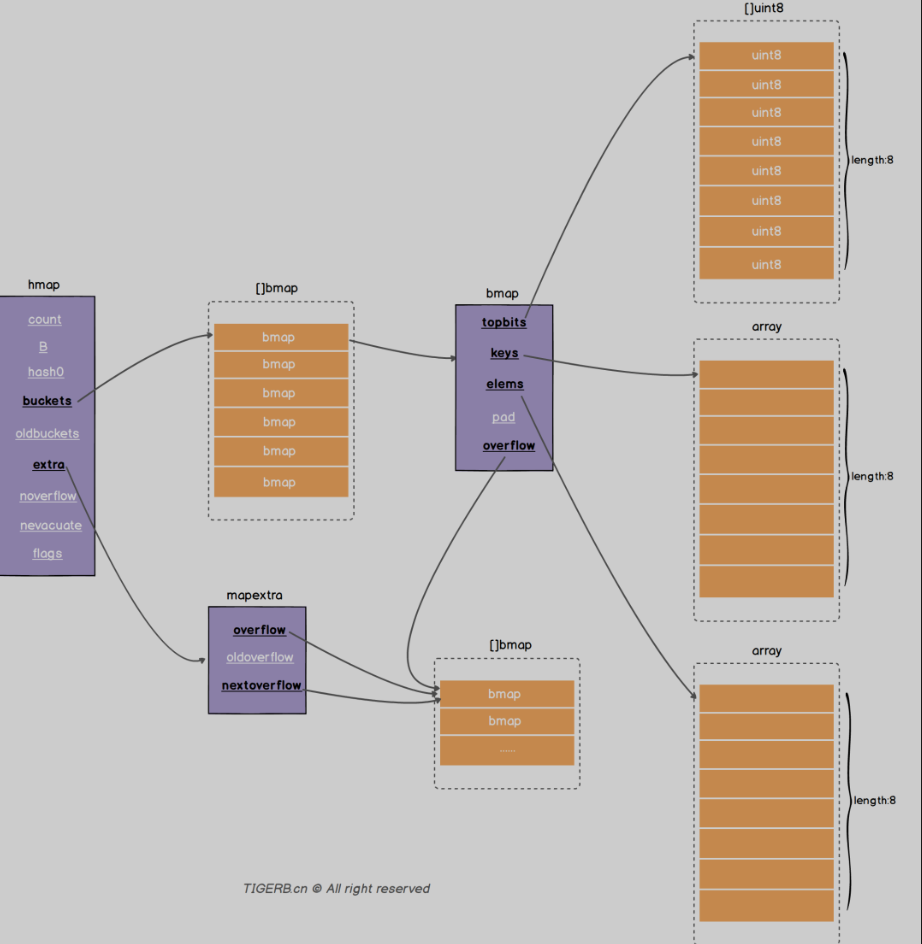

Hmap存在溢出桶 并且当前溢出桶仅仅使用了一个溢出桶的情况
可以看见正常桶和溢出桶后称链表
读取key的大致过程:
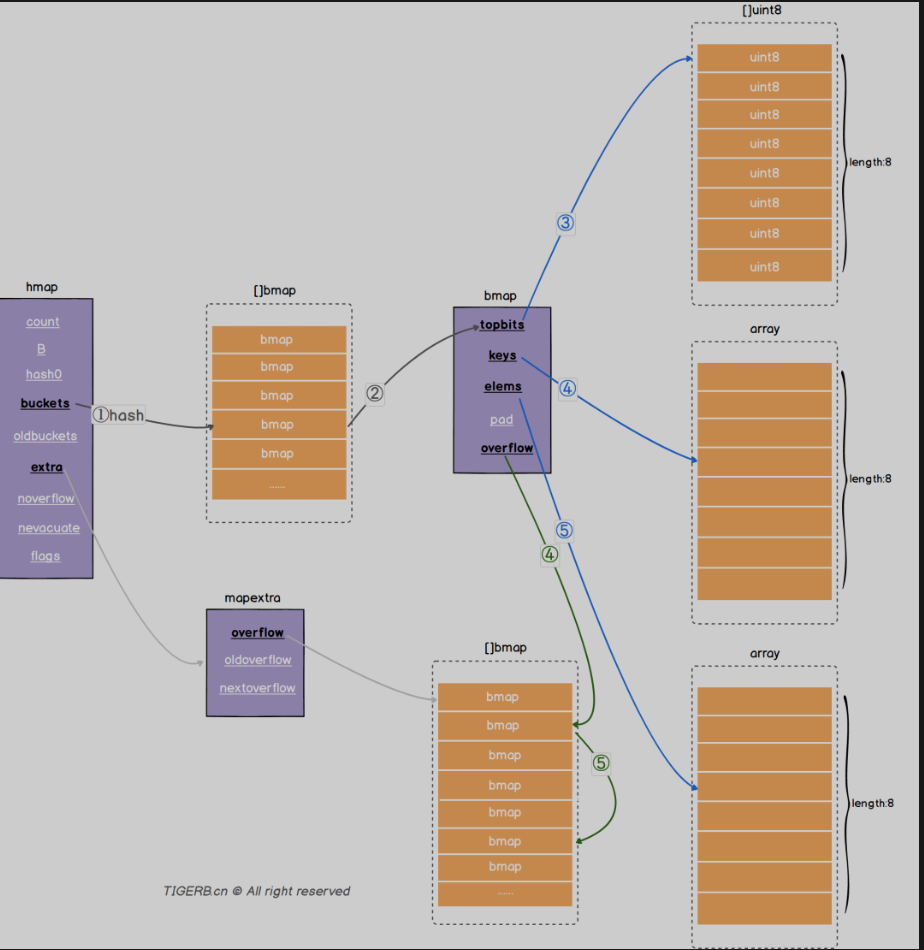

Map Other
哈希表:
哈希查找表用一个哈希函数将key分配到不同的桶(bucket),这样子 开销主要在哈希函数的计算和数组的常数访问时间 哈希碰撞 用链表法 活着 开放地址法 , 前者将bucket实现成一个链表 ,落在一个bucket中间的都插入这个链表 ,后者碰撞发生之后 通过一定的规律 在数组后面选择空的位置 放入新的key
自平衡搜索树法最差搜索效率是o(logN) 哈希表是O(N) , 但是哈希表平均是 O(1),遍历自平衡搜索数 返回的key序列 按照从小到大 但是哈希是乱序的
Map的结构体是hmap 就是hashmap的缩写